Agent Memory
Memory 是在Agent诞生的那一刻就产生的概念。区别于llm或者workflow的直接调用, Agent会把System Prompt和对话历史也一并传到大模型里,这里的对话历史就是最朴素的memory。 对于大模型来说,每一次输入的token数量是有上限的,因此我们会对对话历史做一些总结、裁剪,使这部分context的token占用得到合适的管理。
你好!我记得你叫刘适南
对的,记性不错!
尽管模型的context window在不断提高,为了更准确更合适的context占比,我们当然要寻找效果更佳的方案。 几乎所有的memory方案都遵照着一个流程原则,那就是prepare->use->update.
我们拿Mem0举例,它是一个拥趸众多的开源方案,以下是它的流程图片:
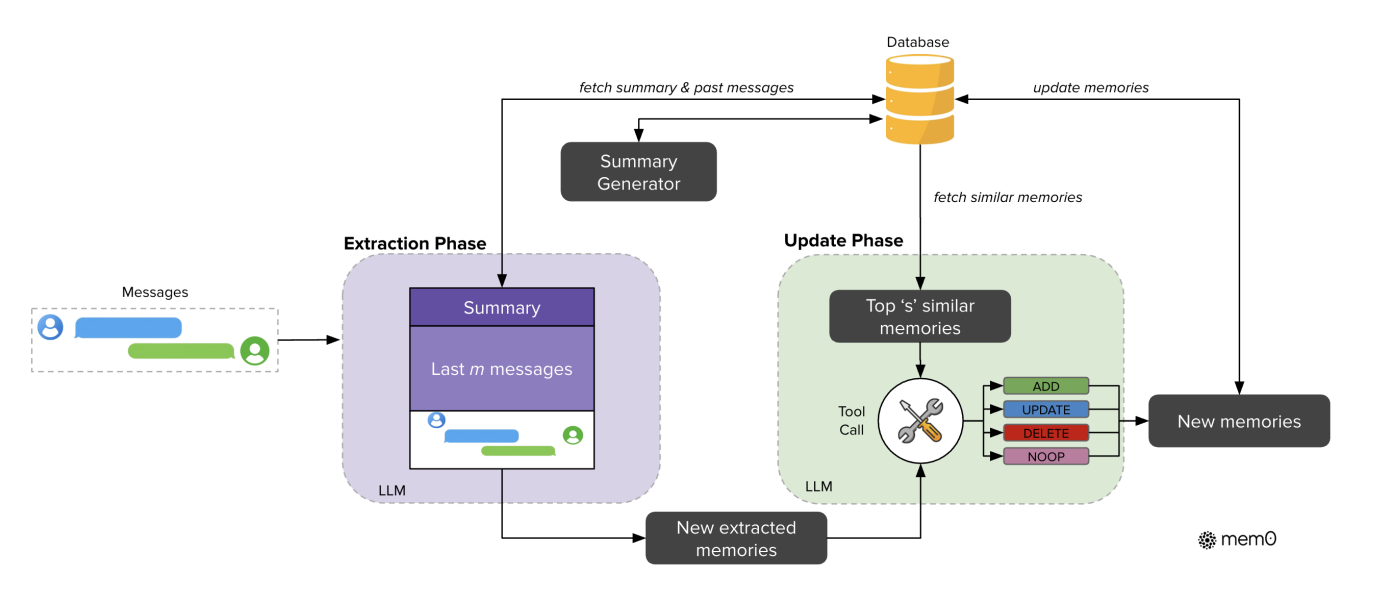
这就是memory的update,不过mem0的处理方式是先提取需要更新的memory,再从旧的数据里找到相似的记忆项,合在一起去做更新。
在我们处理memory的过程中,我们特化了一个Event概念。在解释它之前,我们可以先看看现在Agent的Conversations都是怎么做的:
对话列表
Agent对话是用户发起的,用户可以新建一个空白对话,开启一个没有干扰的对话。这很合理,对吧?历史对话按照上一次访问的顺序排序,你随时可以回到某一个对话中去。当然,Agent的memory就来自于那个对话。
你还记得我叫什么吗?
抱歉,我没有您的姓名信息。请问怎么称呼您?
在另一个新开的对话中,豆包不会记得我的名字。
在投资和金融分析领域,长线的记忆是很重要的。日内和超短线的投资行为是更有实时敏感度的,而长线的投资可能会跨数月或是一年才被再次refer,Agent不能忘记这一点。 另外,你永远不会信任一个经常更换销售的(尤其是金融)公司,你只会在和同一个销售的相处过程中加强和对方的信任。如果每次新开对话就会让Agent忘记和你的所有记忆,感觉起来就和一个陌生人一样,不是吗。 对于有订单信息的平台来说,他们的Agent可以在有授权的情况下调用tools来拿到历史交易信息和相关备注,但是在一个独立Agent中,这些信息只能从历史对话里面找到。当一次新对话中潜在需要数月前的另一个对话信息时,我们没法把这数月间的聊天记录全都塞进请求里。 我们想要在一次请求输入之后,拿到和这个请求相关的聊天记录。听起来很耳熟吧?没错,最native的做法就是向量知识库里做KNN(ANN)。想象你拿着一块磁铁从一堆沙子里面吸铁砂...
向量检索:磁铁吸铁砂
在大模型出现后,除了向量化query塞进知识库之外,我们有了另一种做法。 在mem0的实践中,使用大模型去处理历史信息并总结,效果微妙地更好。因为记忆的消费者就是大模型。 常使用知识库的朋友们都知道,知识库的单次查询是很难拿到所有应得信息的,它的最佳作用是导航到目标区域,然后再根据情况拿到周边的完整情报,比如一组对话,或是一篇文章。对于对话来说,我们很难约束用户有足够的自觉去为每一个话题单独打开一个新对话,上面提到的方式其实效率并不高。
回到最开始提到的Event概念,你可以把它看作是逻辑上的"新对话",我们的目标是提前处理好每一次语句,使它们能够被按照讨论的逻辑主题归类。这样在需要调取它们的时候,我们就能够按照逻辑内容拿到相关的情报了。
我都喜欢"
Agent 知道:
✗ 不送项链(今年送过)
举个例子。 在2024年的时候,圣诞节Agent问对方想要什么礼物,对方回答想要口红。 这个对话被打上了Event Tag,圣诞节、礼物。 在2025年的十二月二十日,我们又讨论到了圣诞节。 这时候该拉取什么信息?圣诞节,和礼物Event,对吧? 我们从圣诞节Tag中拉取到了去年圣诞节的对话,Agent了解到去年送了口红,去了一家西餐厅吃饭。然后我们从礼物Tag中得知,今年我们还送了生日礼物,是一条项链。 那在今年送礼的时候,对方说“随便你送什么我都喜欢”时,Agent就知道我们不该再送口红和项链了——至少不是一模一样的。 发现了吗?这个内容是传统的用户画像无法涵盖的,因为它包含了很多细节,用户画像只会告诉Agent,用户喜欢的礼物是口红。这就像淘宝会在你买了口红之后拼命给你推荐相似的产品一样,有意义,但是很滞后。
RAG在某种程度上也能达到同样的效果(它也是一种预处理),但就像我们刚才所说的,RAG最好用的场合在于索引而非内容抓取,那么在实践过程中,我们应该要把索引到的问答对所在对话的所有内容都放在我们的备选区,然后压缩其中的内容,使得其大小能够满足context window的限制,并且避免无关语句带来的污染。为了避免这里的缺陷,我们在预处理的时候采用Event,也就是逻辑上的分区,来进行限制,这样能保证在提取时能够直接抓取到对应逻辑的内容,和RAG方案不同的是,这部分的内容的整理和压缩发生在预处理阶段,因此在争分夺秒的context准备阶段,早就整理好的Event可以更快被聚合提交,唯一要做的是判断当前的query应该被分配到哪个Event,或是应该隶属于一个新的Event,这也是这个方案的挑战性所在。Knowledge Graph的处理也类似,但是如何推理没有显性表达的关系一直是一个大挑战,而llm更擅长这个。
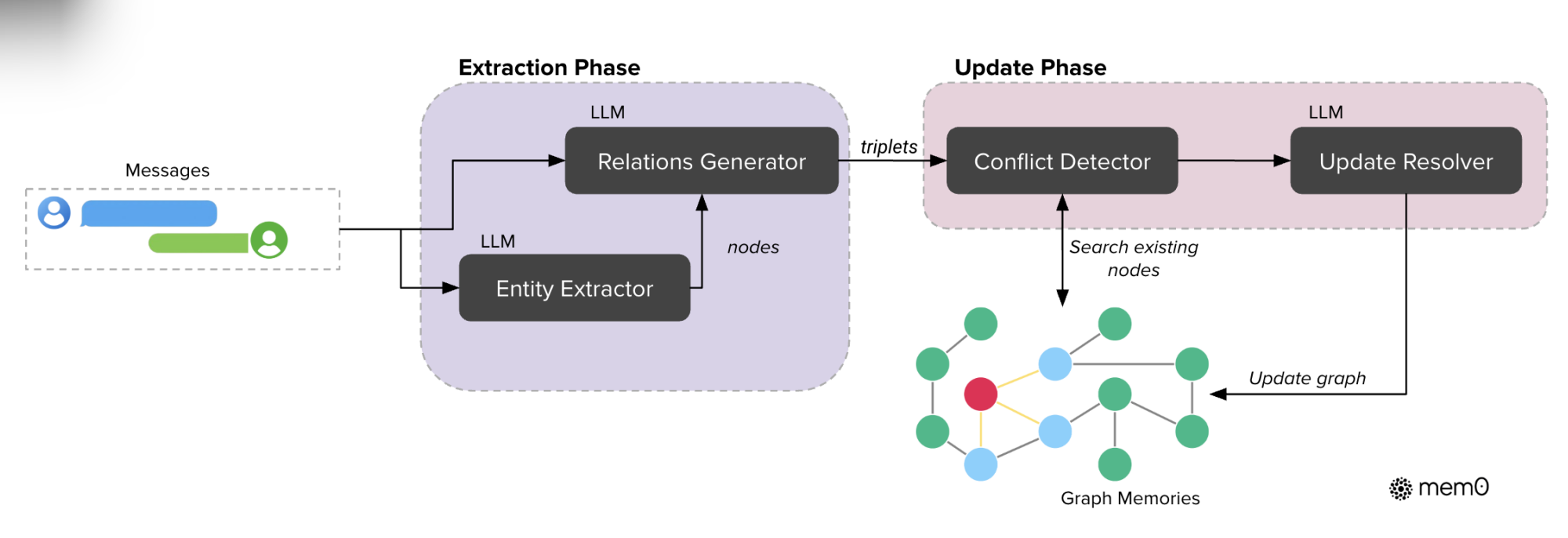 mem0中也有使用图的实现。
mem0中也有使用图的实现。